LSM In A Week - Day 2
by Kyle Smith on 2026-02-05
We've reached the second installment of the LSM storage engine build (see day 1 to follow along). For day 2 of the build we focus on implementing the scan API for the storage engine. This is to allow for reading multiple key-value pairs by providing a byte range. The implementation had some interesting parts, but the most interesting part was the Rust lifetimes shenanigans.
Sections
- Storage Iterator Trait
- Memtable Iterator Implementation
- Merge Iterator Implementation
- Scan Implementation
Storage Iterator Trait
Before we get into the definition of the iterator trait, we look at an interesting property of the storage engine. When we need to perform a read using a given key we need to go through multiple storage layers:
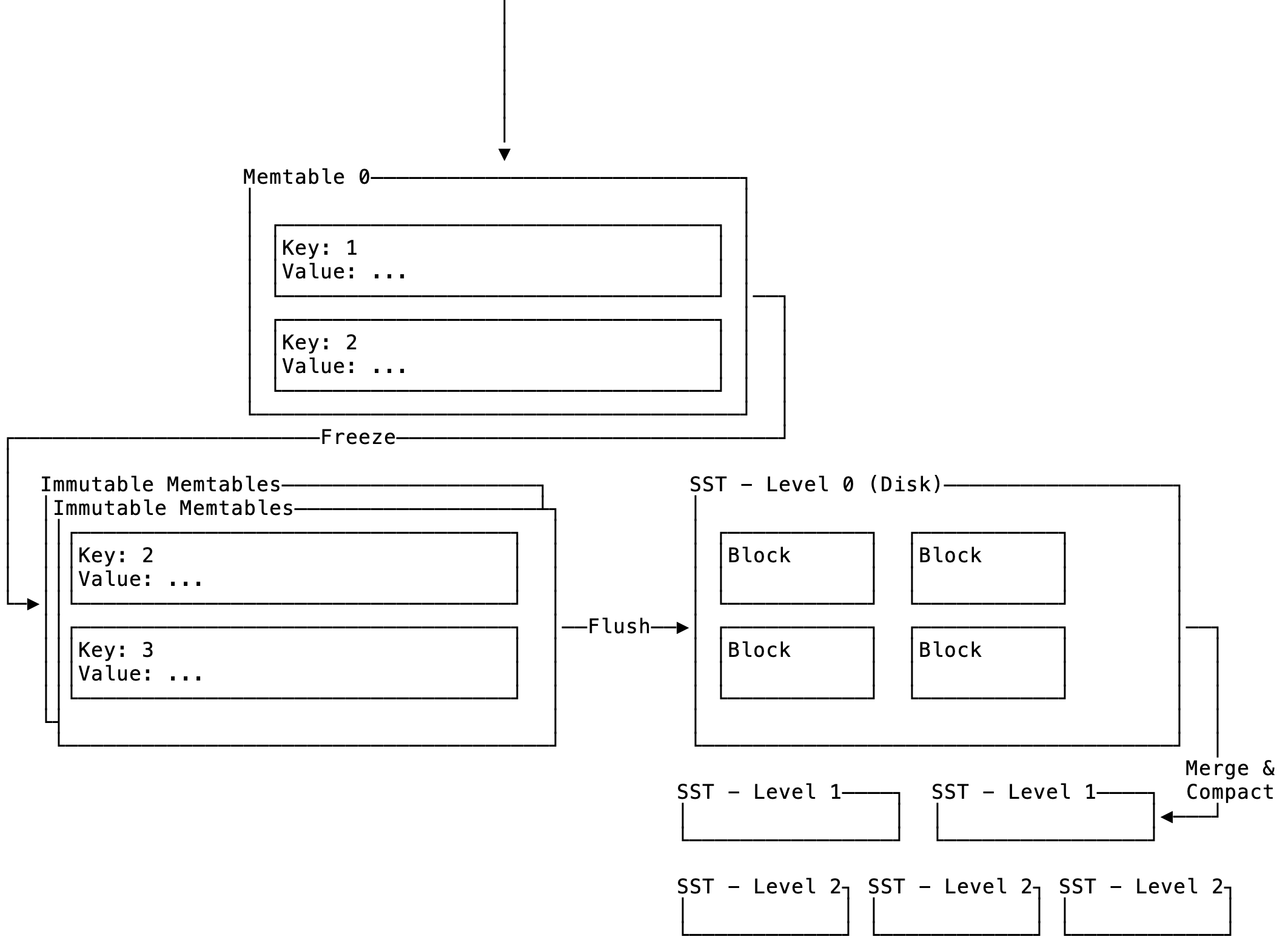 Figure 1: High level of LSM-DB
Figure 1: High level of LSM-DB
The memtables and SST tables make up the different levels in which we can find the stored data. We've not implemented the SST tables yet, but we will need a uniform way to iterate over the contents of these datastructures. This is simple enough, but we are going to take it a step further by requiring that the iterator only borrows the underlying data so we don't actually copy any data. So let's break down the StorageIterator trait to explain what I mean:
pub trait StorageIterator {
// This is the type of the key in the underlying key/value store.
// This is an example of a Generic Associated Type (GAT).
// The key type allows the iterator to be generic over the key type.
// The lifetime annotation requires that the key type is valid for the lifetime of the iterator.
// This communicates that the implementation of this trait allows borrowing from an underlying
// buffer from which the key and value can be borrowed
type KeyType<'a>: PartialEq + Eq + PartialOrd + Ord
where
Self: 'a; // The iterator must live at least as long as lifetime 'a
/// Get the current value, the slice implicitly also has lifetime <'a>
fn value(&self) -> &[u8];
/// Get the current key.
fn key(&self) -> Self::KeyType<'_>;
/// Check if the current iterator is valid.
fn is_valid(&self) -> bool;
/// Move to the next position.
fn next(&mut self) -> anyhow::Result<()>;
/// Number of underlying active iterators for this iterator.
fn num_active_iterators(&self) -> usize {
1
}
}
The storage iterator follows a database cursor design, so the trait allows the iteration to look like the following:
// initialise iter to point to first element
iter.next();
// confirm that iterator is pointing to a key-value pair
while iter.is_valid() {
let key = iter.key();
let value = iter.value();
...
}
This is different from what a typical Rust iterator (docs) implementation looks like:
impl Iterator for MyCustomContainer {
type Item = i32;
fn next(&mut self) -> Option<Self::Item> {
...
}
}
It does however allow us to iterate without additional allocations. Furthermore we also need to be able to report errors when advancing the iterators since not all our data is in-memory, so we need to be able report I/O errors in the next function. Now let's discuss the associated type KeyType, more specifically, this is an example of a Generic Associated Type (GAT). As we saw in the previous post, data is sorted by key in the memtable, so our iterator communicates this to the implementations with the trait bounds PartialEq + Eq + PartialOrd + Ord. We then specify that the KeyType is generic over the lifetime 'a with an additional restriction after the where clause. This restriction states that Self aka the iterator should outlive the lifetime of the key.
Iterator
│
│
└─── current_key: Vec<u8> // underlying buffer
▲
│
│
│
returned &'a [u8] // borrowed data
This allows implementations of this trait to return borrows to the keys or values being iterated over. Which it can safely do since the compiler will ensure that the iterator lives longer than those borrows and this in turn ensures that the borrowed references point to valid data that will not be deallocated.
Memtable Iterator
With the trait in hand we can implement the trait for the memtable.
/// Type alias for SkipMap range iterator
type SkipMapRangeIter<'a> =
crossbeam_skiplist::map::Range<'a, Bytes, (Bound<Bytes>, Bound<Bytes>), Bytes, Bytes>;
/// An iterator over a range of `SkipMap`.
#[self_referencing]
pub struct MemTableIterator {
/// Stores a reference to the skipmap.
map: Arc<SkipMap<Bytes, Bytes>>,
/// Stores a skipmap iterator that refers to the lifetime of `MemTableIterator` itself.
#[borrows(map)] // IMPORTANT
#[not_covariant]
iter: SkipMapRangeIter<'this>,
/// Stores the current key-value pair.
item: (Bytes, Bytes),
}
The SkipList crate we are using provides us with an iterator that supports range queries so we don't have to implement the actual traversal of the SkipList (SkipMapRangeIter). You'll notice we use a macro #[self_referencing] from ouroboros crate, it allows us to use the synthetic 'this lifetime specifier. It communicates that the iterator borrows from another field in the same struct and will be valid as long as the MemTableIterator exists. The #[not_covariant] macro needs a bit more depth to understand fully.
Type Covariance
Type Covariance is a general concept from type theory. Covariance describes how subtype relationships propagate through type constructors. Formally a type constructor is covariant if it preserves the ordering of types, the order of types are from more specific to more generic. For example if you have two classes Dog and Animal, in an object-oriented language you might consider Dog to be a subclass of Animal. It is a specific instance of an animal. So the type ordering is formally expressed as Dog <: Animal, which means if we have a covariant container List (the type constructor) the following is allowed:
animals: List<Animal> = dogs;
animals.add(Cat(...))
where Cat <: Animal.
Now in the world of Rust we can use covariance to reason about lifetimes which are part of the Rust type system. The example that made it clear for me was the following:
fn internal<'short>(s: &'short str) {
...
}
let s: &'static str = "hello";
internal(s);
This is valid, the 'static lifetime annotation states that a value is valid for the entire duration of the program. It is a 'parent' lifetime with nothing greater than it. Our function requires a guarantee that reference s will remain valid for at least 'short. If we express these as types then the following is true: 'short <: 'static, which means the lifetime 'static can be coerced into a shorter lifetime 'short.
So coming back to our MemTableIterator we need to prevent shortening of the generic lifetime, now it took me a while to actually understand why this is a problem. Usually this is fine as a lifetime essentially defines a scope (not always true, but this is an intuitive mental model for myself), so you can visualise lifetimes as follows:
fn some_fn<'a, T>(num: &'a T) where T: Display {
...
}
fn main() {
'x: {
let num = 39;
'y: { // scope/lifetime start
let num_ref = &'y num;
'z: {
some_fn(num_ref)
}
} // scope/lifetime end
}
}
So in the above case we have 'z <: 'y, where 'y is used to communicate that num will live as least as long as 'y. So in the child lifetime 'z it does make sense that this should be allowed since num will live at least as long as 'z. However, consider if we do something like:
fn make() -> SelfRef<'static> {
let mut s = SelfRef {
data: "hello".to_string(),
slice: "",
};
let ptr = s.data.as_str();
unsafe { // bypassing compiler checks
std::ptr::write(&mut s.slice, ptr);
}
// s = { data: "hello", slice: Ptr -> "hello" }
s
}
fn shorten<'short>(x: SelfRef<'static>) -> SelfRef<'short> {
x // covariance in effect here
}
let mut x = shorten(make()); // x 'short <: x 'static
x.data = "goodbye".to_string(); // new string allocation -> new memory location
// x.ptr is dangling at this point
Relating this back to the MemTableIterator struct you can see that map is the data and iter is the pointer.
The iterator trait implementation is then pretty simple:
impl MemTableIterator {
fn entry_to_item(entry: Option<Entry<'_, Bytes, Bytes>>) -> (Bytes, Bytes) {
entry
.map(|x| (x.key().clone(), x.value().clone()))
.unwrap_or_else(|| (Bytes::from_static(&[]), Bytes::from_static(&[])))
}
}
impl StorageIterator for MemTableIterator {
type KeyType<'a> = &'a [u8];
fn value(&self) -> &[u8] {
&self.borrow_item().1[..]
}
fn key(&self) -> &'a [u8] {
&self.borrow_item().0[..]
}
fn is_valid(&self) -> bool {
// check if we the current key is empty
!self.borrow_item().0.is_empty()
}
fn next(&mut self) -> Result<()> {
// advance iterator
let entry = self.with_iter_mut(|iter| MemTableIterator::entry_to_item(iter.next()));
// update current item
self.with_mut(|x| *x.item = entry);
Ok(())
}
}
One important note is that entry_to_item looks like it is actually copying the data, but Bytes is effectively Arc<[u8]> so it is just copying the reference.
Merge Iterator Implementation
Next we will implement the merge iterator. The merge iterator is responsible for merging the results of multiple iterators into a single sorted iterator. This is done by maintaining a min-heap of iterators and advancing the iterator with the smallest key. This is similar to the merge step in the merge sort algorithm, except we're doing a k-way merge. The iterator solves the problem of providing a single stream of keys that are sorted and deduplicated with the latest version of that key.
The merge algorithm needs to keep track of both the key version and key ordering. Since we need to process a specific iterator at a time, a queue makes sense. We also need something that maintains that order as an invariant, so a min-heap is a natural choice. The LSM-tree makes constructing the min-heap pretty easy, since all the data is already sorted by key and we also know how to sort the keys by version due to the storage hierarchy. The mutable memtable holds the latest version (of the keys that were in recent writes), the immutable memtables are also sorted in order they were frozen. The merge iterator will also need to handle SST tables, but we will worry about that later. So we use our recently implemented memtable iterator in conjunction with an index to use as a pseudo version.
struct HeapWrapper<I: StorageIterator>(pub usize, pub Box<I>);
impl<I: StorageIterator> Ord for HeapWrapper<I> {
fn cmp(&self, other: &Self) -> cmp::Ordering {
self.1
.key()
.cmp(&other.1.key())
.then(self.0.cmp(&other.0))
.reverse()
}
}
We implement the Ord trait for our HeapWrapper struct which will be used by the heap when sorting. We first sort by key and then the index.
With this we can construct the min-heap, which looks like the following:
Current────────────┐
│ │
│ A, D, E │────┐ Min-Heap────────────────┐
│ │ │ │┌─────────────────────┐│
└──────────────────┘ │ ││ A, D, E ││
│ │└─────────────────────┘│
Frozen Memtable - 1┐ │ │ │
│ │ │ │┌─────────────────────┐│
│ A, B, F, ... │────┤ ││ A, B, F, ... ││
│ │ │ │└─────────────────────┘│
└──────────────────┘ │ │ │
├────▶│┌─────────────────────┐│
Frozen Memtable - 2┐ │ ││ C, B, F, ... ││
│ │ │ │└─────────────────────┘│
│ D, E, F, ... │────┤ │ │
│ │ │ │┌─────────────────────┐│
└──────────────────┘ │ ││ D, E, F, ... ││
│ │└─────────────────────┘│
Frozen Memtable - 3┐ │ │ │
│ │ │ └───────────────────────┘
│ C, B, F, ... │────┘
│ │
└──────────────────┘
The min-heap will ensure that the iterator with the minimum key and version is at the top, in our example above the mutable memtable holds both the minimum key A and the latest version, followed by the most recently frozen memtable since it also has A as the first key.
Now since we are using Rust there is some complexity in actually implementing due to the borrow checker. We use the std::collections::BinaryHeap as our heap implementation (docs). This is implemented as max-heap which is why we reverse our ordering in the HeapWrapper Ord trait implementation.
// construct a max-heap sorted by first key and index of iterator
let mut heap = BinaryHeap::new();
for (i, iter) in iters.into_iter().enumerate() {
if iter.is_valid() {
// need valid iterators since heap needs to sort iterators
heap.push(HeapWrapper(i, iter));
}
}
The MergeIterator also implements the StorageIterator trait so we need to talk about lifetimes again:
impl<I: 'static + for<'a> StorageIterator<KeyType<'a> = KeySlice<'a>>> StorageIterator
for MergeIterator<I>
{
type KeyType<'a> = KeySlice<'a>;
...
}
The first line packs a lot of information:
-
I: 'static: The storage iterator does not borrow from something outside of itself. It simplifies the lifetime parameters as it does not require us to add an additional lifetime. -
for<'a>: Quantification over all possible lifetimes that can be assigned to'a. -
StorageIterator< KeyType < 'a > = KeySlice < 'a >>>: Using the quantification to restrict the associated type defined in the trait. The'alifetime is used to constrain the references returned by the iterator (recall we borrow keys and values from the iterator).
The next interesting part of the MergeIterator implementation is advancing the iterator. When we construct the iterator we have a field current which we use to keep track of the iterator that has the smallest key. When advancing the iterator we first need to ensure we have the latest version of a particular key:
fn next(&mut self) -> Result<()> {
// get a mutable reference to the field (Option<HeapWrapper<StorageIterator>>)
let current = self.current.as_mut().unwrap();
while let Some(mut inner_iter) = self.iters.peek_mut() {
// assert heap invariant (will alert if we mess something up in our implementation)
debug_assert!(current.1.key() <= inner_iter.1.key());
// check if the keys are the same
if inner_iter.1.key() == current.1.key() {
// yes the keys are the same, advance inner iterator
// Rust syntax: binding @ pattern
// We're basically saying that if an error occurs store it in e
if let e @ Err(_) = inner_iter.1.next() {
// something went wrong, need to remove the PeekMut<T> guard
// since when drop(PeekMut<T>) is called it will attempt to
// read from the iterator to sort heap again, so we
// protect against reading an invalid iterator here
PeekMut::pop(inner_iter);
return e;
}
} else {
// keys are not the same so nothing to do
break;
}
// drop(inner_iter) called here, so heap is sorted before next iteration
}
The inner_iter can only iterate over a single element at a time, since calling next on the iterator can cause the heap invariant to no longer be valid, so we have to drop the guard PeekMut (returned by .peek_mut) before interacting with it again. Consider the following scenario to visualise it:
┌──────────────────────────────────────────────────────────┐
│ Current────────────┐ │
│ │ │ Current───────────────┐ │
│ │ A, D, E │────┐ │ A, D, E │ │
│ │ │ │ └─────────────────────┘ │
│ └──────────────────┘ │ │
│ │ │
│ Frozen Memtable - 1┐ │ Min-Heap────────────────┐ │
│ │ │ │ │inner_mut─────────────┐│ │
│ │ A, Z, F, ... │────┤ ││ A, Z, F, ... ││ │
│ │ │ │ │└─────────────────────┘│ │
│ └──────────────────┘ │ │ │ │
│ │ │┌─────────────────────┐│ │
│ Frozen Memtable - 2┐ │ ││ C, B, F, ... ││ │
│ │ │ ├────▶│└─────────────────────┘│ │
│ │ D, E, F, ... │────┤ │ │ │
│ │ │ │ │┌─────────────────────┐│ │
│ └──────────────────┘ │ ││ D, E, F, ... ││ │
│ │ │└─────────────────────┘│ │
│ Frozen Memtable - 3┐ │ │ │ │
│ │ │ │ └───────────────────────┘ │
│ │ C, B, F, ... │────┘ │
│ │ │ │
│ └──────────────────┘ │
└──────────────────────────────────────────────────────────┘
│
│
Remove Duplicate
A
│
▼
┌───────────────────────────────────────────────────────────┐
│ Current────────────┐ │
│ │ │ Current───────────────┐ │
│ │ A, D, E │────┐ │ A, D, E │ │
│ │ │ │ └─────────────────────┘ │
│ └──────────────────┘ │ │
│ │ │
│ Frozen Memtable - 1┐ │ Min-Heap────────────────┐ │
│ │ │ │ │inner_mut─────────────┐│ │
│ │ A, Z, F, ... │────┤ ││ Z, F, ... ││ │
│ │ │ │ │└─────────────────────┘│ │
│ └──────────────────┘ │ │ │ │
│ │ │┌─────────────────────┐│ │
│ Frozen Memtable - 2┐ │ ││ C, B, F, ... ││ │
│ │ │ ├────▶│└─────────────────────┘│ │
│ │ D, E, F, ... │────┤ │ │ │
│ │ │ │ │┌─────────────────────┐│ │
│ └──────────────────┘ │ ││ D, E, F, ... ││ │
│ │ │└─────────────────────┘│ │
│ Frozen Memtable - 3┐ │ │ │ │
│ │ │ │ └───────────────────────┘ │
│ │ C, B, F, ... │────┘ │
│ │ │ │
│ └──────────────────┘ │
│ │
└───────────────────────────────────────────────────────────┘
│
│
Heapify
│
▼
┌───────────────────────────────────────────────────────────┐
│ Current────────────┐ │
│ │ │ Current───────────────┐ │
│ │ A, D, E │────┐ │ A, D, E │ │
│ │ │ │ └─────────────────────┘ │
│ └──────────────────┘ │ │
│ │ │
│ Frozen Memtable - 1┐ │ Min-Heap────────────────┐ │
│ │ │ │ │inner_mut─────────────┐│ │
│ │ A, Z, F, ... │────┤ ││ C, B, F, ... ││ │
│ │ │ │ │└─────────────────────┘│ │
│ └──────────────────┘ │ │ │ │
│ │ │┌─────────────────────┐│ │
│ Frozen Memtable - 2┐ │ ││ D, E, F, ... ││ │
│ │ │ ├────▶│└─────────────────────┘│ │
│ │ D, E, F, ... │────┤ │ │ │
│ │ │ │ │┌─────────────────────┐│ │
│ └──────────────────┘ │ ││ Z, F, ... ││ │
│ │ │└─────────────────────┘│ │
│ Frozen Memtable - 3┐ │ │ │ │
│ │ │ │ └───────────────────────┘ │
│ │ C, B, F, ... │────┘ │
│ │ │ │
│ └──────────────────┘ │
└───────────────────────────────────────────────────────────┘
Since the inner iterators are sorted we can be sure when the while loop resolves we've processed all duplicates. We can also safely advance the current iterator.
We do however need to do some validation:
// advance
current.1.next()?;
// this is needed since advancing the iterator might be at the end
// so we need to move to next one if that is the case
if !current.1.is_valid() {
if let Some(iter) = self.iters.pop() {
*current = iter;
}
return Ok(());
}
We need to ensure that a valid iterator is set as the current iterator. If we are done with the current iterator it will no longer be valid and we can move on to the next iterator. Another case we need to check is since we advanced the iterator it may no longer hold the smallest key, so we need to consult the heap again:
// since we advanced the iterator we need to
// still ensure whether the current iterator still has the smallest key
if let Some(mut inner_iter) = self.iters.peek_mut() {
// if the current key is smaller than the key currently at the top of the heap
// put the current iterator back into the heap and use the old heap top
// it is guaranteed that the inner is not equal to current as we removed them
if *current < *inner_iter {
std::mem::swap(&mut *inner_iter, current);
}
}
// inner_iter out of scope so heap will be sorted again
Now with this in hand we can finally implement the scan method.
Scan Implementation
The API for the scan method is defined simply as:
pub fn scan(
&self,
lower: Bound<&[u8]>,
upper: Bound<&[u8]>,
) -> Result<FusedIterator<LsmIterator>> {
It requires a lower and upper bound, which allows you to express different ranges:
/// std::ops::Bound
pub enum Bound<T> {
/// An inclusive bound.
Included(T),
/// An exclusive bound.
Excluded(T),
/// An infinite endpoint. Indicates that there is no bound in this direction.
Unbounded,
}
The FusedIterator and LsmIterator are not super interesting, they are simply wrapping our merge-iterator. The most important implementation detail is that the LsmIterator will not return a key if its associated value's latest state is deleted. Since deleting keys is only a concept in the top-level LSM storage engine api.
The scan method operates on a transactional view of the stored data. It takes a read lock and then copies the current state, which is used to construct the iterators. It is still possible for the mutable memtable to be updated before the iterator is constructed.
/// Create an iterator over a range of keys.
pub fn scan(
&self,
lower: Bound<&[u8]>,
upper: Bound<&[u8]>,
) -> Result<FusedIterator<LsmIterator>> {
let snapshot = {
let guard = self.state.read();
Arc::clone(&guard) // stable pointer to current version of state
};
// prepare iterators for memtables (current memtable + frozen memtables)
let mut memtable_iters = Vec::with_capacity(snapshot.imm_memtables.len() + 1);
// construct memtable iterators
memtable_iters.push(Box::new(snapshot.memtable.scan(lower, upper)));
for memtable in snapshot.imm_memtables.iter() {
memtable_iters.push(Box::new(memtable.scan(lower, upper)));
}
// construct merge iterator
let memtable_merge_iter = MergeIterator::create(memtable_iters);
// create lsm iterator from memtable merge iterator
let lsm_iter = LsmIterator::new(memtable_merge_iter)?;
Ok(FusedIterator::new(lsm_iter))
}
Conclusion
Wow that was much more complicated than expected, but I can confidently say it was rewarding for developing my understanding of the Rust lifetime system. It's still something to get used to, but I can now appreciate what it communicates to the programmer and the overall design of the Rust language.