LSM In A Week - Day 1
by Kyle Smith on 2026-02-01
This will be a sort of journal while I implement an LSM-backed storage engine following this guide. Each blog will just discuss some of the implementation details and optimisations I think are cool. A storage engine is the core component of a Database Management System (DBMS) and it is responsible for handling the CRUD operations for the data stored on physical devices or in memory. WiredTiger is the default storage engine used with MongoDB and at its core it is simply a key/value store, its core data structure is a B-tree. A B-tree is a self-balancing tree that maintains sorted data and allows inserts and searches. However, if you extend your scope beyond amortized analysis, B-trees are more efficient for reads than writes. One of the issues is that writes are done in place, which requires rebalancing, node splitting and merging operations, this makes concurrency more complicated due to the complex locking required. Skipping over the many optimisations that can be made (see what PostgreSQL does here), enter the LSM-tree or log-structured-merge tree.
Sections
What is an LSM-tree?
An LSM-tree is a multi-level, on-disk data structure that maintains a sorted list of keys. It consists of two top-level components:
- Memtable - in-memory data structure
- Sorted String Table (SST) - on-disk data structure (will explore this later, only done with the implementation for the memtable)
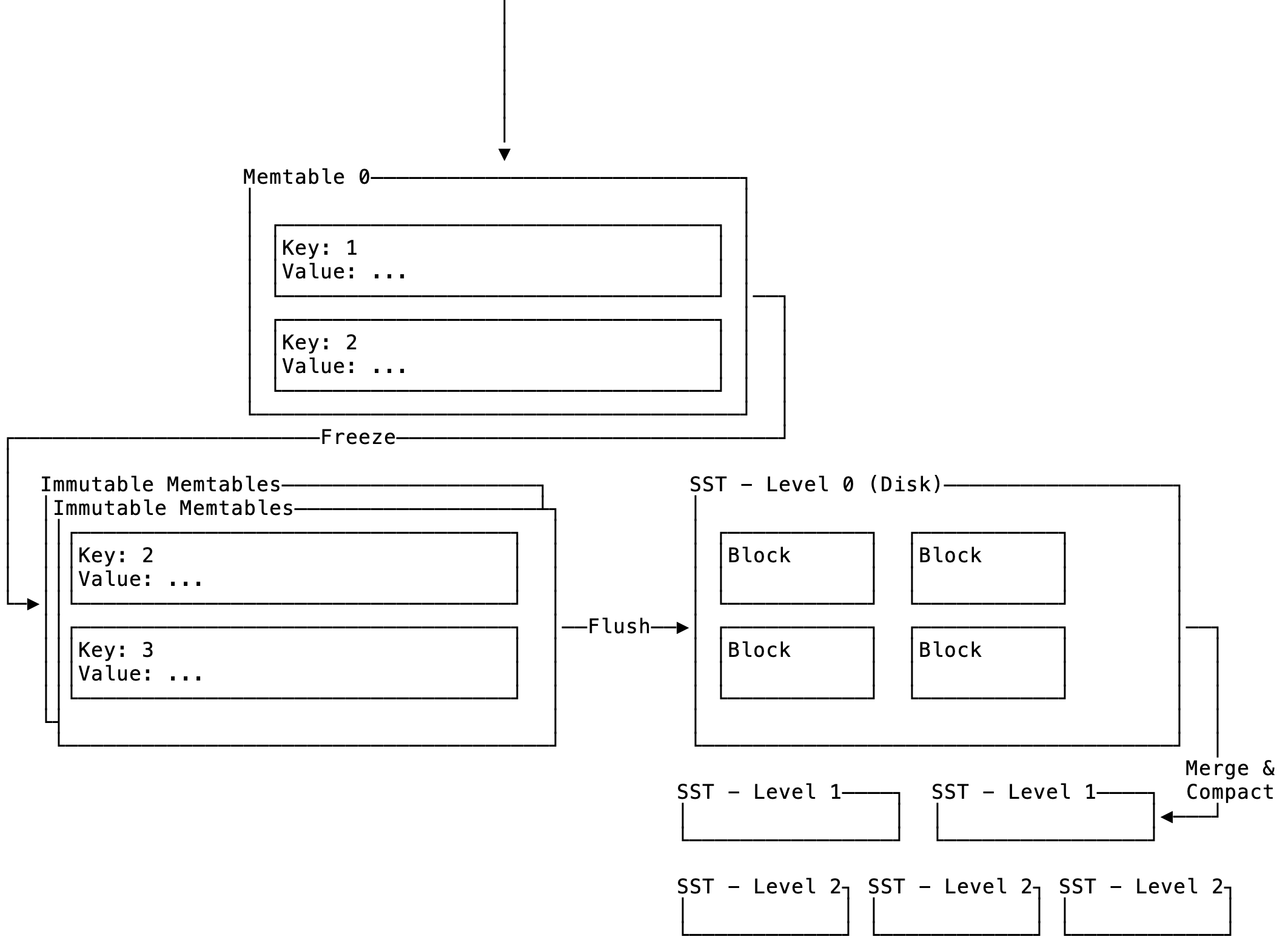 Figure 1: Highlevel of LSM-DB
Figure 1: Highlevel of LSM-DB
The memtable is a key/value store and is where the latest values are written to and read from. Typically this is implemented with a skip-list. A skip-list is a special form of linked-list that maintains a sorted list of keys and is a stack of linked lists on top of each other to allow for more efficient searching:
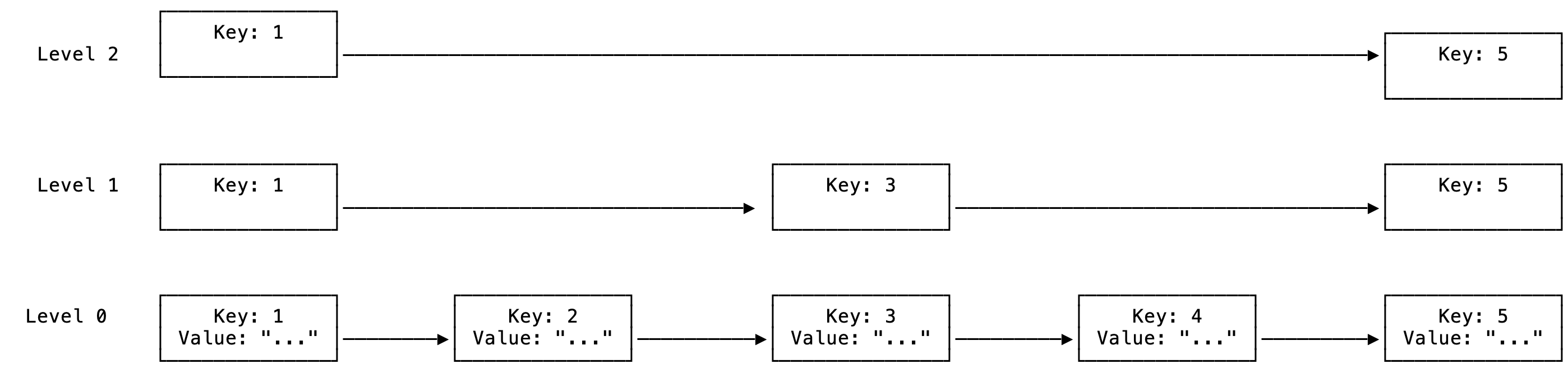 Figure 2: Simple skip-list
Figure 2: Simple skip-list
The skip list gives you multiple ways to search for a particular key by using express lanes based on key ordering. Since this is a linked-list it also works well in a concurrent environment where there are reads and writes, since you only have to worry about the exclusive access to the pointers of the node where the insert is happening. Reading or even updating another node does not affect it and can also be implemented lock-free with atomics.
Memtable
The first thing to implement is the memtable as it is where all reads and writes will go through (SSTs come later). The memtable struct looks like the following:
pub struct MemTable {
map: Arc<SkipMap<Bytes, Bytes>>, // Atomic reference counted skip-list
wal: Option<Wal>, // Write-Ahead log (full implementation later down the line)
id: usize, // ID for this memtable
approximate_size: Arc<AtomicUsize>, // Best-effort atomic counter approximation of the size in bytes of the memtable
}
- The
mapis the underlying sorted key/value data structure, it does not have to be a SkipList. walis the write-ahead log and is used to store the operations made to the skip-list in the case of a process crash we can reconstruct the state of the memtable. This is needed since the memtable lives in volatile memory and has not yet been persisted to disk.approximate_size: This is an approximation of the size in bytes of the space occupied by the skip-list keys and values. It is an approximation as in the implementation if two threads write the same key at the same time it will count these twice. It is mainly used to determine when to freeze the memtable before it is flushed to disk.
The only two functions we need to worry about at this point are get and put, which look pretty boring (at the moment):
/// get value by key
pub fn get(&self, key: &[u8]) -> Option<Bytes> {
self.map.get(key).map(|e| e.value().clone())
}
/// put key and value, performs an upsert if key exists
/// thread-safe
pub fn put(&self, key: &[u8], value: &[u8]) -> Result<()> {
let put_size = key.len() + value.len();
// add to skip-list
self.map
.insert(Bytes::copy_from_slice(key), Bytes::copy_from_slice(value));
// since this is best-effort we don't restrict the memory ordering
self.approximate_size
.fetch_add(put_size, std::sync::atomic::Ordering::Relaxed);
// all good
Ok(())
}
LSM Storage State
The memtable forms part of the current LSM storage engine state, it is where writes always go and it is the first place where we check when searching for a specific key. The state of the engine is fully described as follows:
pub struct LsmStorageState {
/// The current memtable.
pub memtable: Arc<MemTable>,
/// Immutable memtables, from latest to earliest.
pub imm_memtables: Vec<Arc<MemTable>>,
/// L0 SSTs, from latest to earliest.
pub l0_sstables: Vec<usize>,
/// SsTables sorted by key range; L1 - L_max for leveled compaction, or tiers for tiered
/// compaction.
pub levels: Vec<(usize, Vec<usize>)>,
/// SST objects.
pub sstables: HashMap<usize, Arc<SsTable>>,
}
Currently we only care about memtable and imm_memtables, the immutable memtables are full and will eventually be flushed to disk.
Concurrency in storage engine
Now we get to the interesting stuff, the interface for the LSM storage engine is given by the following struct:
pub(crate) struct LsmStorageInner {
pub(crate) state: Arc<RwLock<Arc<LsmStorageState>>>,
pub(crate) state_lock: Mutex<()>,
path: PathBuf,
pub(crate) block_cache: Arc<BlockCache>,
next_sst_id: AtomicUsize,
pub(crate) options: Arc<LsmStorageOptions>,
pub(crate) compaction_controller: CompactionController,
pub(crate) manifest: Option<Manifest>,
pub(crate) mvcc: Option<LsmMvccInner>,
pub(crate) compaction_filters: Arc<Mutex<Vec<CompactionFilter>>>,
}
The only fields I need to interact with at this point are state and state_lock. To understand the reasoning behind the mutex and read-write lock protecting these fields we need to look at the write path:
/// Put a key-value pair into the storage by writing into the current memtable.
pub fn put(&self, key: &[u8], value: &[u8]) -> Result<()> {
let size;
{
// take read lock
let guard = self.state.read();
// put key/value into current mutable memtable
guard.memtable.put(key, value)?;
// get approximate size
size = guard.memtable.approximate_size();
// drop is called implicitly on guard (releasing read lock)
}
// check if we need to freeze the memtable
self.try_freeze(size)
}
So the most interesting part (for me at least) in this implementation is that we can take a read lock to perform a write operation. This is due to the memtable being itself thread-safe with the use of atomics, so the hot-path for writing is pretty cheap. Now the real concurrency challenges come into play when we need to freeze the memtable.
fn try_freeze(&self, estimated_size: usize) -> Result<()> {
if estimated_size >= self.options.target_sst_size {
let state_lock = self.state_lock.lock();
/* Critical section start */
// acquire read lock so that we can check current state
// We take a combination of the state_lock and read lock instead of just a write lock
// to ensure that gets, puts and deletes still can still execute (technically only gets if the above condition is true)
let guard = self.state.read();
// double confirm, since another thread might have already updated the memtable
if guard.memtable.approximate_size() >= self.options.target_sst_size {
// we are going to update the state so we don't want to still have a read lock
drop(guard);
// freeze memtable passing lock to indicate that we hold a lock on the state
self.force_freeze_memtable(&state_lock)?;
}
/* Critical section end */
}
Ok(())
}
There are a few interesting things to look at here, first is the double-locking pattern. We do a cheap comparison between the estimated size and the target SST size to determine if the memtable has reached capacity and should be frozen. If this is the case then the the executing thread will attempt to acquire the state_lock, which is a plain mutex and marks the start of a critical section. Now the key thing to realise here is that at this point we are actually not blocking interaction with the memtable, even when taking the read lock. So technically during this function other threads might be reading or updating the memtable. I also want to highlight a really nice pattern that Rust showcases here with the stack_lock being passed to the force_freeze_memtable function. The type of the function local variable state_lock is a MutexGuard. Usually you can access the data is protecting by dereferencing it, but in this case it's not protecting a specific piece of data. We pass it to the force_freeze_memtable as a kind of promise that: "I have the lock to ensure the state struct is not going to change".
/// Force freeze the current memtable to an immutable memtable
pub fn force_freeze_memtable(&self, _state_lock_observer: &MutexGuard<'_, ()>) -> Result<()> {
let memtable_id = self.next_sst_id();
let mut guard = self.state.write();
let mut snapshot = guard.as_ref().clone();
let old_memtable = std::mem::replace(
&mut snapshot.memtable,
Arc::new(MemTable::create(memtable_id)),
);
// Add the memtable to the immutable memtables (newest first).
snapshot.imm_memtables.insert(0, old_memtable.clone());
// Update the snapshot.
*guard = Arc::new(snapshot);
drop(guard);
Ok(())
}
The force_freeze_memtable is responsible for moving the current memtable to the frozen memtable list and creating the new memtable where data will be written to. Also notice that we don't use the mutex guard, but we've encoded in the contract of this function that it needs to execute under a mutex (that's really cool!).
Conclusion
This was a very interesting start to the implementation of an LSM storage engine. It has made me appreciate the amount of detail and nuance involved in the implementation. I’ve only implemented the most basic part, yet it’s already dense with techniques and optimizations. So looking forward to what lies ahead.